Overview
![]()

Overview
GPUStack is an open-source GPU cluster manager designed for efficient AI model deployment. It configures and orchestrates inference engines — vLLM, SGLang, TensorRT-LLM, or your own — to optimize performance across GPU clusters.
-
Multi-Cluster GPU Management
Manages GPU clusters across multiple environments. This includes on-premises servers, Kubernetes clusters, and cloud providers.
-
Pluggable Inference Engines
Automatically configures high-performance inference engines such as vLLM, SGLang, and TensorRT-LLM. You can also add custom inference engines as needed.
-
Day 0 Model Support
GPUStack's pluggable engine architecture enables you to deploy new models on the day they are released.
-
Performance-Optimized
Offers pre-tuned modes for low latency or high throughput. Supports extended KV cache (LMCache, HiCache) and speculative decoding (EAGLE3, MTP).
-
Enterprise-Grade Operations
Offers support for automated failure recovery, load balancing, monitoring, authentication, and access control.
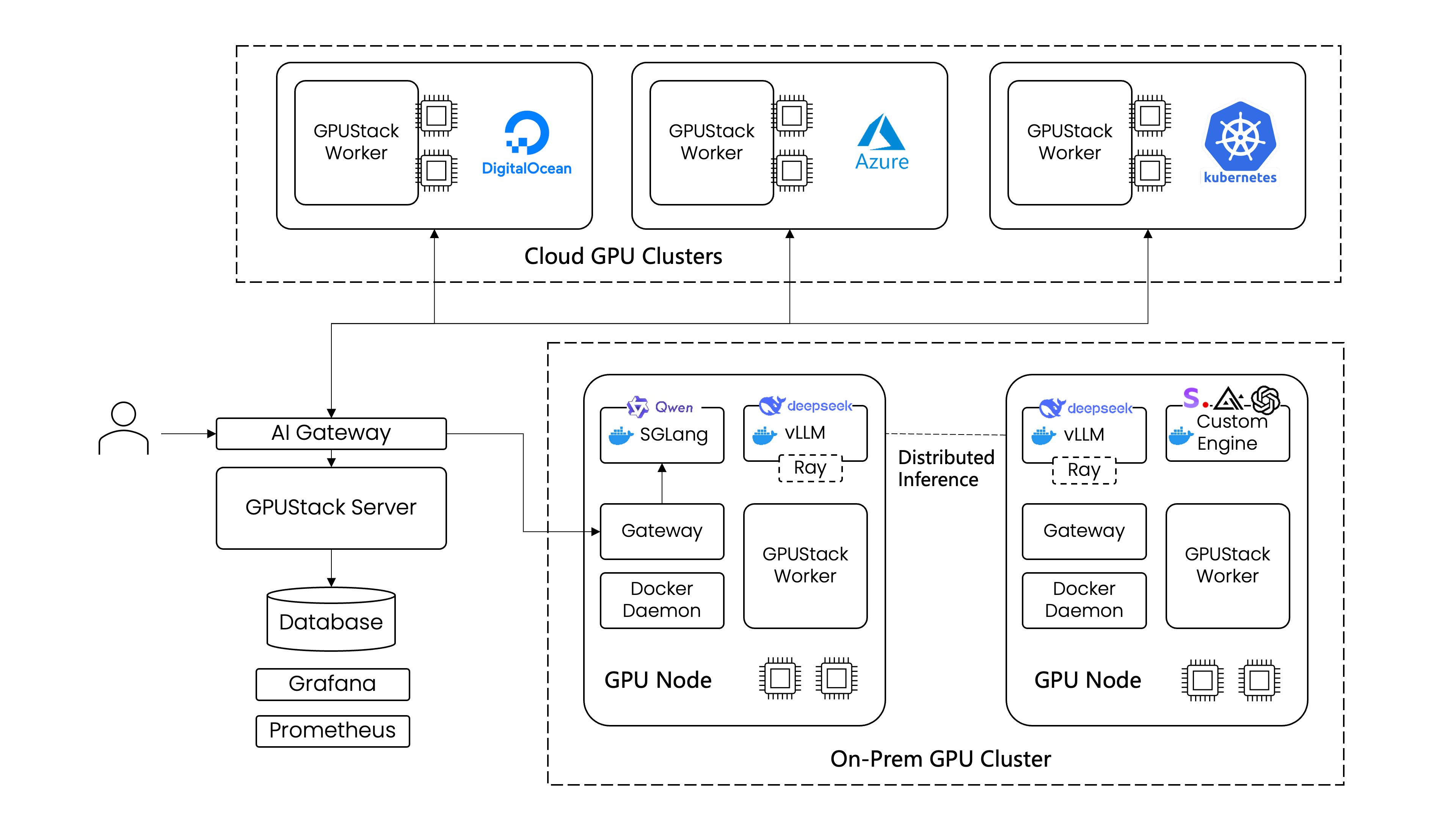
Architecture
GPUStack enables development teams, IT organizations, and service providers to deliver Model-as-a-Service at scale. It supports industry-standard APIs for LLM, voice, image, and video models. The platform includes built-in user authentication and access control, real-time monitoring of GPU performance and utilization, and detailed metering of token usage and API request rates.
The figure below illustrates how a single GPUStack server can manage multiple GPU clusters across both on-premises and cloud environments. The GPUStack scheduler allocates GPUs to maximize resource utilization and selects the appropriate inference engines for optimal performance. Administrators also gain full visibility into system health and metrics through integrated Grafana and Prometheus dashboards.
Optimized Inference Performance
GPUStack's automated engine selection and parameter optimization deliver strong inference performance out of the box. The following figure shows throughput improvements over default vLLM configurations:
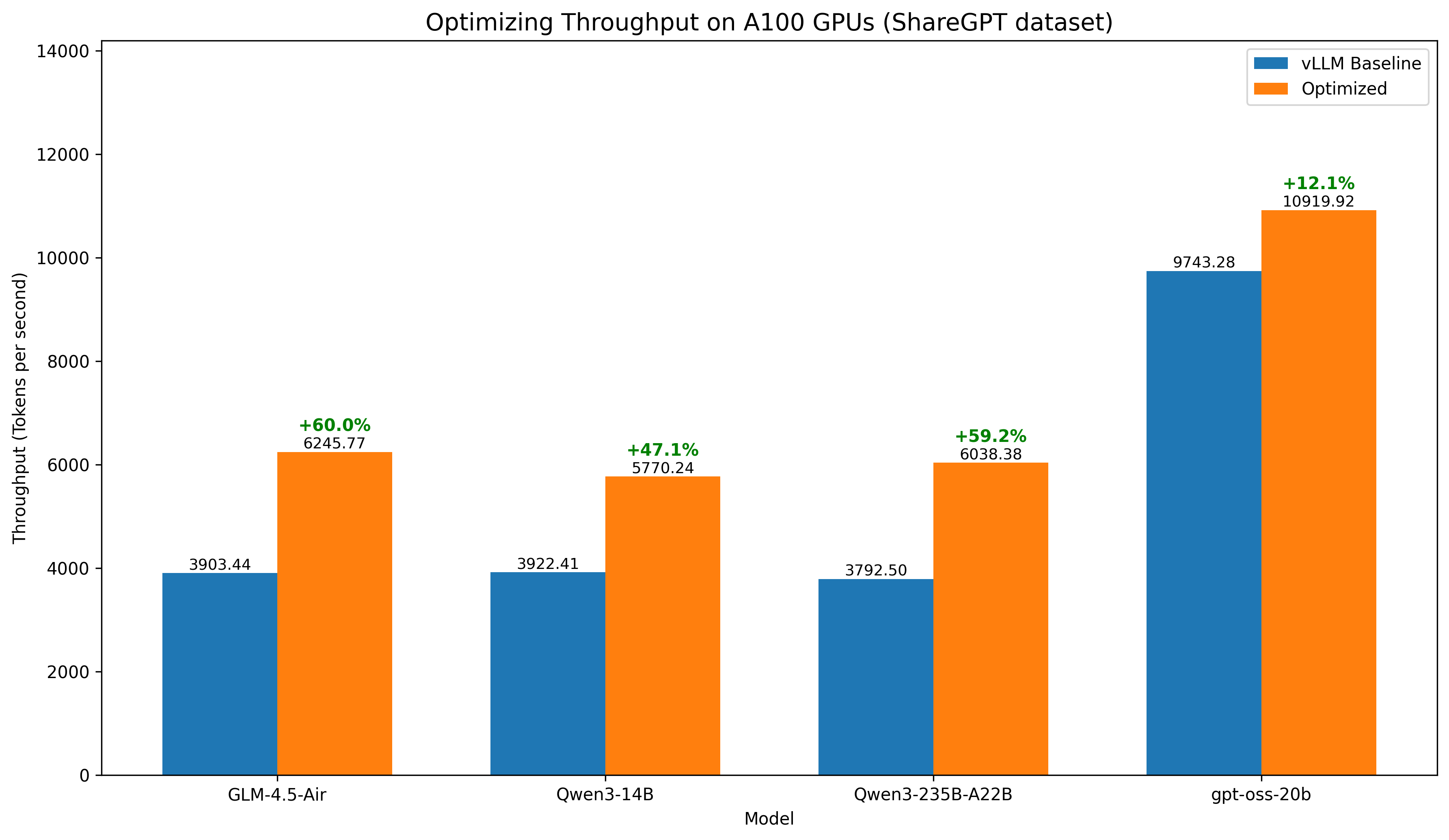
For detailed benchmarking methods and results, visit our Inference Performance Lab.
Supported Accelerators
GPUStack supports a wide range of accelerators for AI inference:







For detailed requirements and setup instructions, see the Installation Requirements documentation.