Optimizing DeepSeek-V3.2 Throughput on NVIDIA H200 GPUs Conclusion
Serving Command -m sglang.launch_server --model deepseek-ai/DeepSeek-V3.2 \
./tool_chat_template_deepseekv32.jinja \
8 --dp-size 8 --enable-dp-attention
deepseek-v3 \
deepseekv32
Link for tool_chat_template_deepseekv32.jinja .
Based on the below benchmarks, we recommend the above configuration for optimizing DeepSeek-V3.2 throughput on 8×H200 .
Parallelism and Tool Call Configuration provide the largest performance gains and are therefore included in the recommended command. Context Length Adjustment can further improve throughput but is highly workload-dependent and should be tuned according to actual usage. While Attention Backend optimizations show positive effects, their gains are relatively small and may vary across datasets, so they are not included in the default recommendation.
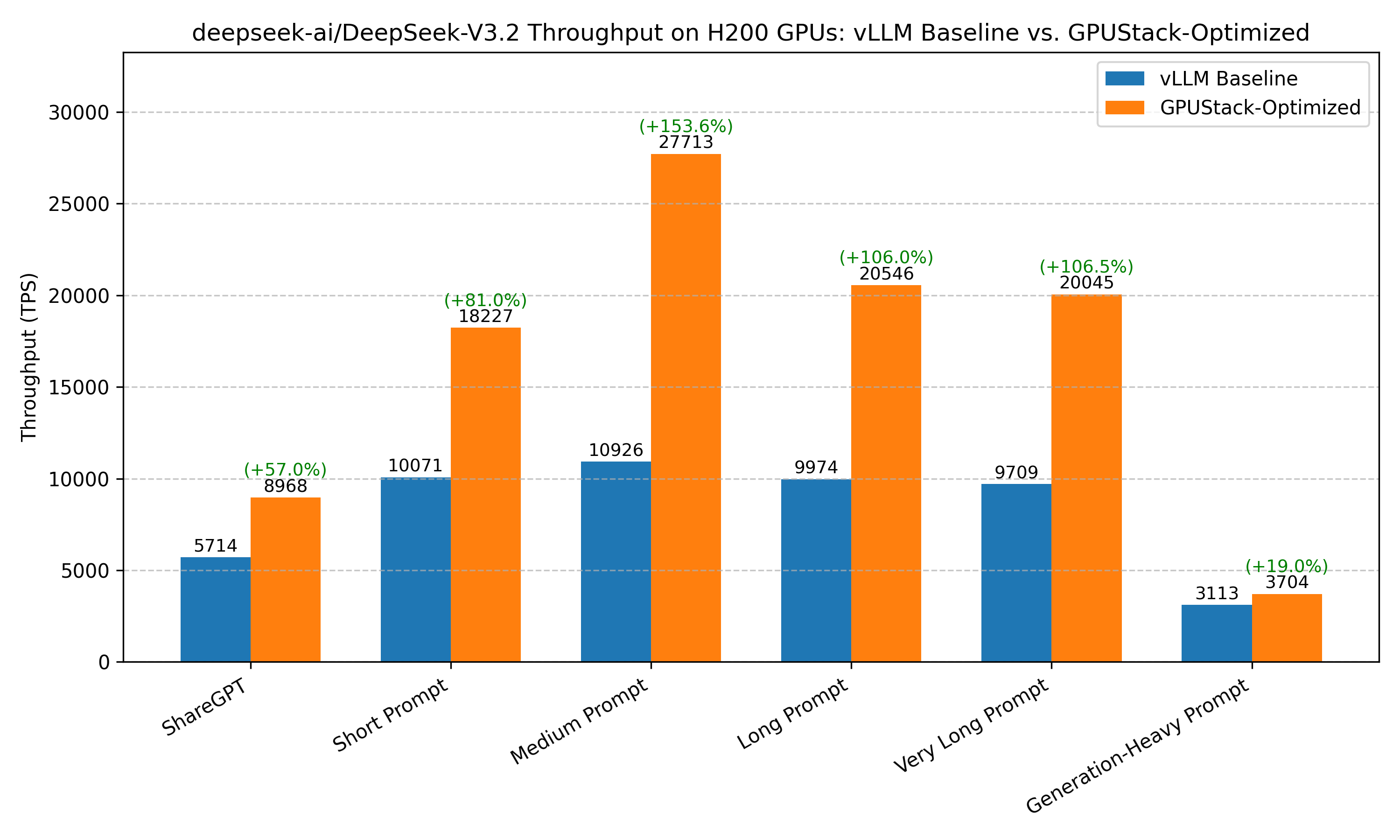
Comparison of benchmark results before and after optimization:
Benchmark Case baseline (vLLM without any optimizations) Optimized ShareGPT Total TPS: 5713.95 Total TPS: 8968.32 (+56.95%) Short Prompt Total TPS: 10071.49 Total TPS: 18227.38 (+80.98%) Medium Prompt Total TPS: 10925.59 Total TPS: 27712.54 (+153.65%) Long Prompt Total TPS: 9974.26 Total TPS: 20545.67 (+105.99%) Very Long Prompt Total TPS: 9709.27 Total TPS: 20045.18 (+106.45%) Generation-Heavy Prompt Total TPS: 3112.52 Total TPS: 3703.98 (+19.0%)
Note
Our benchmark tests do not cover all possible optimization combinations. For example, we select the inference engine that performs best under its default configuration as the starting point for further tuning. This pruning approach yields a local optimum, which may not be the global optimum. There are other optimization methods that depend on specific user scenarios, including max batch size, schedule configuration, extended KV cache, CUDA graph, etc. The conclusions in this document can serve as a starting point for more targeted optimizations. The tests are conducted on specific hardware and software setups. Advances in the inference engine may lead to new conclusions. If there are any missing points or updates reflecting new changes, please let us know .
Optimization Objective Achieve high throughput under high-concurrency request scenarios.
Experimental Setup Model deepseek-ai/DeepSeek-V3.2
Hardware 8 × NVIDIA H200 SXM GPUs on a single node.
Engine Version vLLM: v0.13.0 SGLang: v0.5.6.post2 TensorRT-LLM: 1.2.0rc5 Benchmark Dataset ShareGPT Random dataset with varying sequence lengths: Very long prompt: 32000 input tokens, 100 output tokens Long prompt: 4000 input tokens, 200 output tokens Medium prompt: 2000 input tokens, 100 output tokens Short prompt: 128 input tokens, 4 output tokens Generation-Heavy Prompt: 1K input tokens, 2K output tokens Benchmark Script We use the vLLM bench CLI tool to benchmark the model performance. The following command is used to run the benchmark:
# Prepare the ShareGPT dataset
https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered/resolve/main/ShareGPT_V3_unfiltered_cleaned_split.json
# Benchmark on ShareGPT dataset
bench serve --model deepseek-ai/DeepSeek-V3.2 --backend openai-chat --endpoint /v1/chat/completions --dataset-name sharegpt --dataset-path ShareGPT_V3_unfiltered_cleaned_split.json --num-prompts 1000
# Benchmark on random dataset (fixed seed for reproducibility)
bench serve --model deepseek-ai/DeepSeek-V3.2 --backend openai-chat --endpoint /v1/chat/completions --dataset-name random --random-input-len 4000 --random-output-len 200 --num-prompts 500 --seed 42
Experiment Results 1. Baseline of the Inference Engine vLLM
Serving script serve deepseek-ai/DeepSeek-V3.2 -tp 8 --tokenizer-mode deepseek_v32 --reasoning-parser deepseek_v3
Benchmark result
SGLang
Serving script -m sglang.launch_server --model-path deepseek-ai/DeepSeek-V3.2 --host 0 .0.0.0 --port 8000 \
./tool_chat_template_deepseekv32.jinja \
8
Benchmark result
TensorRT-LLM
Serving script /workspace/DeepSeek-v3.2 --tp_size 8
Benchmark result
Result: vLLM (5713.95 tok/s) > SGLang(3012.37 tok/s) > TensorRT-LLM (1732.48 tok/s)
2. Optimizing vLLM Parallelism: DP+EP Serving script # 81920 is half context, full context OOM
serve deepseek-ai/DeepSeek-V3.2 --tokenizer-mode deepseek_v32 --reasoning-parser deepseek_v3 \
1 -dp 8 --enable-expert-parallel --max-model-len 81920
Benchmark result
Parallelism: DCP Serving script serve deepseek-ai/DeepSeek-V3.2 -tp 8 --tokenizer-mode deepseek_v32 --reasoning-parser deepseek_v3 \
8
DeepSeek V3.2 relies on the FlashMLA sparse attention backend, which currently does not expose softmax log-sum-exp (LSE) during the decode phase. Since Decode Context Parallelism (DCP) requires softmax LSE for correct cross-rank aggregation, DCP is not supported with FlashMLA at this time, leading to a runtime failure in vLLM. This limitation has been discussed in the vLLM repository (see issue #27544 ).
MTP Serving script serve deepseek-ai/DeepSeek-V3.2 -tp 8 --tokenizer-mode deepseek_v32 --reasoning-parser deepseek_v3 \
{ "method" :"mtp" ,"num_speculative_tokens" :1}
Benchmark result
Turn off DeepGEMM in vLLM Serving script export VLLM_USE_DEEP_GEMM = 0
serve deepseek-ai/DeepSeek-V3.2 -tp 8 --tokenizer-mode deepseek_v32 --reasoning-parser deepseek_v3
Benchmark result
Serving script serve deepseek-ai/DeepSeek-V3.2 -tp 8 --tokenizer-mode deepseek_v32 --reasoning-parser deepseek_v3 --tool-call-parser deepseek_v32 --enable-auto-tool-choice
Benchmark result
Context Length Adjustment Serving script serve deepseek-ai/DeepSeek-V3.2 -tp 8 --tokenizer-mode deepseek_v32 --reasoning-parser deepseek_v3 --max-model-len 32768
Benchmark result ============ Serving Benchmark Result ============
requests: 1000
duration ( s) : 75 .12
input tokens: 219111
generated tokens: 196938
throughput ( req/s) : 13 .31
token throughput ( tok/s) : 2621 .48
output token throughput ( tok/s) : 6293 .00
concurrent requests: 1000 .00
Token throughput ( tok/s) : 5538 .11
to First Token----------------
TTFT ( ms) : 10439 .14
TTFT ( ms) : 10296 .60
TTFT ( ms) : 23842 .17
per Output Token ( excl. 1st token) ------
TPOT ( ms) : 357 .68
TPOT ( ms) : 223 .35
TPOT ( ms) : 1169 .74
Latency----------------
ITL ( ms) : 154 .24
ITL ( ms) : 78 .13
ITL ( ms) : 660 .95
==================================================
Attention Backend: CUTLASS_MLA Serving script export VLLM_ATTENTION_BACKEND = "CUTLASS_MLA"
serve deepseek-ai/DeepSeek-V3.2 -tp 8 --tokenizer-mode deepseek_v32 --reasoning-parser deepseek_v3
ValueError: Selected backend AttentionBackendEnum.CUTLASS_MLA is not valid for this configuration. Reason: ['sparse not supported', 'compute capability not supported']
Attention Backend: FLASHMLA Serving script export VLLM_ATTENTION_BACKEND = "FLASHMLA"
ValueError: Selected backend AttentionBackendEnum.FLASHMLA is not valid for this configuration. Reason: ['sparse not supported']
Attention Backend: TRITON_MLA Serving script export VLLM_ATTENTION_BACKEND = "TRITON_MLA"
serve deepseek-ai/DeepSeek-V3.2 -tp 8 --tokenizer-mode deepseek_v32 --reasoning-parser deepseek_v3
ValueError: Selected backend AttentionBackendEnum.TRITON_MLA is not valid for this configuration. Reason: ['sparse not supported']
3. Optimizing SGLang Parallelism: TP+DP Attention Serving script -m sglang.launch_server --model-path deepseek-ai/DeepSeek-V3.2 --host 0 .0.0.0 --port 8000 \
./tool_chat_template_deepseekv32.jinja \
8 --enable-dp-attention
Benchmark result
Parallelism: TP+DP+DP Attention Serving script -m sglang.launch_server --model-path deepseek-ai/DeepSeek-V3.2 --host 0 .0.0.0 --port 8000 \
./tool_chat_template_deepseekv32.jinja \
8 --dp-size 8 --enable-dp-attention
Benchmark result
Parallelism: TP+DP+DP Attention+EP Serving script -m sglang.launch_server --model-path deepseek-ai/DeepSeek-V3.2 --host 0 .0.0.0 --port 8000 \
./tool_chat_template_deepseekv32.jinja \
8 --dp-size 8 --enable-dp-attention --ep-size 8
Benchmark result
MTP Serving script -m sglang.launch_server --model-path deepseek-ai/DeepSeek-V3.2 --host 0 .0.0.0 --port 8000 \
8 \
EAGLE --speculative-num-steps 1 --speculative-eagle-topk 1 --speculative-num-draft-tokens 2
Benchmark result
Turn off DeepGEMM Serving script export SGLANG_ENABLE_JIT_DEEPGEMM = 0
-m sglang.launch_server --model-path deepseek-ai/DeepSeek-V3.2 --host 0 .0.0.0 --port 8000 \
./tool_chat_template_deepseekv32.jinja \
8
The server fails to start when DeepGEMM is disabled.
Serving script -m sglang.launch_server --model-path deepseek-ai/DeepSeek-V3.2 --host 0 .0.0.0 --port 8000 \
./tool_chat_template_deepseekv32.jinja \
8 \
\
8 \
deepseek-v3 \
deepseekv32
Benchmark result
Context Length Adjustment Serving script -m sglang.launch_server --model-path deepseek-ai/DeepSeek-V3.2 --host 0 .0.0.0 --port 8000 \
./tool_chat_template_deepseekv32.jinja \
8 \
\
8 \
deepseek-v3 \
deepseekv32 \
= 32768
Benchmark result
KV Cache DType Serving script -m sglang.launch_server --model-path deepseek-ai/DeepSeek-V3.2 --host 0 .0.0.0 --port 8000 \
./tool_chat_template_deepseekv32.jinja \
8 \
\
8 \
deepseek-v3 \
deepseekv32 \
= 32768 \
fp8_e4m3
Benchmark result
Attention Backend: fa3 + fa3 Serving script -m sglang.launch_server --model-path deepseek-ai/DeepSeek-V3.2 --host 0 .0.0.0 --port 8000 \
./tool_chat_template_deepseekv32.jinja \
8 \
\
8 \
deepseek-v3 \
deepseekv32 \
= 32768 \
nsa \
fa3 \
fa3
Benchmark result
Attention Backend: flashmla_sparse + flashmla_kv Serving script -m sglang.launch_server --model-path deepseek-ai/DeepSeek-V3.2 --host 0 .0.0.0 --port 8000 \
./tool_chat_template_deepseekv32.jinja \
8 \
\
8 \
deepseek-v3 \
deepseekv32 \
= 32768 \
nsa \
flashmla_sparse \
flashmla_kv
Benchmark result
4. Optimizing TensorRT-LLM Parallelism: TP+EP Serving script /workspace/DeepSeek-v3.2 --tp_size 8 --ep_size 8 --pp_size 1
Benchmark result
Turn off DeepGEMM Serving script export TRTLLM_DG_ENABLED = 0
/workspace/DeepSeek-v3.2 --tp_size 8 --ep_size 8 --pp_size 1
Benchmark result
Summary of Optimization Options Optimization Option Throughput Improvement Parallelism +28.66% Tool Call Configuration +13.94% Context Length Adjust +4.47% Attention Backend +2.49% KV Cache Dtype - MTP - DeepGEMM - Total(vs Baseline) +56.97%
Other Benchmark Cases We further benchmarked the optimized configuration to evaluate its generalization under various workloads.
Baseline serving script serve deepseek-ai/DeepSeek-V3.2 -tp 8 --tokenizer-mode deepseek_v32 --reasoning-parser deepseek_v3
Baseline benchmark results # random 128 input
============ Serving Benchmark Result ============
requests: 1000
duration ( s) : 13 .11
input tokens: 128000
generated tokens: 4000
throughput ( req/s) : 76 .30
token throughput ( tok/s) : 305 .20
output token throughput ( tok/s) : 1029 .00
concurrent requests: 1000 .00
Token throughput ( tok/s) : 10071 .49
to First Token----------------
TTFT ( ms) : 5786 .15
TTFT ( ms) : 4666 .02
TTFT ( ms) : 12922 .46
per Output Token ( excl. 1st token) ------
TPOT ( ms) : 781 .80
TPOT ( ms) : 687 .63
TPOT ( ms) : 1637 .52
Latency----------------
ITL ( ms) : 586 .79
ITL ( ms) : 664 .73
ITL ( ms) : 3545 .51
==================================================
# random 2K input
============ Serving Benchmark Result ============
requests: 500
duration ( s) : 96 .10
input tokens: 1000000
generated tokens: 50000
throughput ( req/s) : 5 .20
token throughput ( tok/s) : 520 .27
output token throughput ( tok/s) : 4085 .00
concurrent requests: 500 .00
Token throughput ( tok/s) : 10925 .59
to First Token----------------
TTFT ( ms) : 45667 .57
TTFT ( ms) : 43997 .53
TTFT ( ms) : 87384 .57
per Output Token ( excl. 1st token) ------
TPOT ( ms) : 354 .59
TPOT ( ms) : 433 .59
TPOT ( ms) : 452 .30
Latency----------------
ITL ( ms) : 353 .26
ITL ( ms) : 68 .59
ITL ( ms) : 661 .87
==================================================
# random 4K input
============ Serving Benchmark Result ============
requests: 500
duration ( s) : 210 .54
input tokens: 2000000
generated tokens: 100000
throughput ( req/s) : 2 .37
token throughput ( tok/s) : 474 .96
output token throughput ( tok/s) : 2769 .00
concurrent requests: 500 .00
Token throughput ( tok/s) : 9974 .26
to First Token----------------
TTFT ( ms) : 103386 .88
TTFT ( ms) : 97324 .68
TTFT ( ms) : 200514 .23
per Output Token ( excl. 1st token) ------
TPOT ( ms) : 226 .74
TPOT ( ms) : 246 .98
TPOT ( ms) : 275 .68
Latency----------------
ITL ( ms) : 228 .79
ITL ( ms) : 49 .50
ITL ( ms) : 683 .63
==================================================
# random 32k input
============ Serving Benchmark Result ============
requests: 100
duration ( s) : 330 .61
input tokens: 3200000
generated tokens: 10000
throughput ( req/s) : 0 .30
token throughput ( tok/s) : 30 .25
output token throughput ( tok/s) : 384 .00
concurrent requests: 100 .00
Token throughput ( tok/s) : 9709 .27
to First Token----------------
TTFT ( ms) : 164003 .81
TTFT ( ms) : 164174 .93
TTFT ( ms) : 325134 .01
per Output Token ( excl. 1st token) ------
TPOT ( ms) : 472 .52
TPOT ( ms) : 512 .36
TPOT ( ms) : 514 .39
Latency----------------
ITL ( ms) : 477 .69
ITL ( ms) : 741 .90
ITL ( ms) : 949 .57
==================================================
random input + 2k generation
============ Serving Benchmark Result ============
requests: 100
duration ( s) : 96 .39
input tokens: 100000
generated tokens: 200000
throughput ( req/s) : 1 .04
token throughput ( tok/s) : 2075 .01
output token throughput ( tok/s) : 2598 .00
concurrent requests: 100 .00
Token throughput ( tok/s) : 3112 .52
to First Token----------------
TTFT ( ms) : 4789 .20
TTFT ( ms) : 4590 .83
TTFT ( ms) : 10608 .88
per Output Token ( excl. 1st token) ------
TPOT ( ms) : 45 .72
TPOT ( ms) : 45 .83
TPOT ( ms) : 47 .44
Latency----------------
ITL ( ms) : 46 .34
ITL ( ms) : 43 .13
ITL ( ms) : 44 .29
==================================================
Optimized serving script -m sglang.launch_server --model deepseek-ai/DeepSeek-V3.2 \
./tool_chat_template_deepseekv32.jinja \
8 --dp-size 8 --enable-dp-attention \
deepseek-v3 \
deepseekv32 \
= 32768 \
nsa \
fa3 \
fa3
Optimized benchmark results # random 128 input
============ Serving Benchmark Result ============
requests: 984
duration ( s) : 7 .13
input tokens: 125952
generated tokens: 3936
throughput ( req/s) : 138 .09
token throughput ( tok/s) : 552 .34
output token throughput ( tok/s) : 2526 .00
concurrent requests: 984 .00
Token throughput ( tok/s) : 18227 .38
to First Token----------------
TTFT ( ms) : 4441 .81
TTFT ( ms) : 4685 .89
TTFT ( ms) : 6735 .22
per Output Token ( excl. 1st token) ------
TPOT ( ms) : 776 .55
TPOT ( ms) : 714 .97
TPOT ( ms) : 1659 .07
Latency----------------
ITL ( ms) : 465 .93
ITL ( ms) : 59 .97
ITL ( ms) : 4564 .16
==================================================
# random 2K input
============ Serving Benchmark Result ============
requests: 500
duration ( s) : 37 .89
input tokens: 1000000
generated tokens: 50000
throughput ( req/s) : 13 .20
token throughput ( tok/s) : 1319 .64
output token throughput ( tok/s) : 9477 .00
concurrent requests: 500 .00
Token throughput ( tok/s) : 27712 .54
to First Token----------------
TTFT ( ms) : 18696 .78
TTFT ( ms) : 18939 .89
TTFT ( ms) : 32138 .14
per Output Token ( excl. 1st token) ------
TPOT ( ms) : 192 .24
TPOT ( ms) : 189 .20
TPOT ( ms) : 349 .96
Latency----------------
ITL ( ms) : 189 .18
ITL ( ms) : 55 .05
ITL ( ms) : 219 .74
==================================================
# random 4K input
============ Serving Benchmark Result ============
requests: 500
duration ( s) : 102 .21
input tokens: 2000000
generated tokens: 100000
throughput ( req/s) : 4 .89
token throughput ( tok/s) : 978 .37
output token throughput ( tok/s) : 7180 .00
concurrent requests: 500 .00
Token throughput ( tok/s) : 20545 .67
to First Token----------------
TTFT ( ms) : 44019 .81
TTFT ( ms) : 40806 .24
TTFT ( ms) : 90171 .38
per Output Token ( excl. 1st token) ------
TPOT ( ms) : 177 .95
TPOT ( ms) : 161 .14
TPOT ( ms) : 321 .10
Latency----------------
ITL ( ms) : 177 .57
ITL ( ms) : 49 .55
ITL ( ms) : 224 .52
==================================================
# random 32k input
============ Serving Benchmark Result ============
requests: 100
duration ( s) : 160 .14
input tokens: 3200000
generated tokens: 10000
throughput ( req/s) : 0 .62
token throughput ( tok/s) : 62 .45
output token throughput ( tok/s) : 1189 .00
concurrent requests: 100 .00
Token throughput ( tok/s) : 20045 .18
to First Token----------------
TTFT ( ms) : 83964 .72
TTFT ( ms) : 88265 .70
TTFT ( ms) : 157005 .30
per Output Token ( excl. 1st token) ------
TPOT ( ms) : 246 .26
TPOT ( ms) : 229 .67
TPOT ( ms) : 514 .42
Latency----------------
ITL ( ms) : 244 .63
ITL ( ms) : 33 .21
ITL ( ms) : 898 .58
==================================================
random input + 2k generation
============ Serving Benchmark Result ============
requests: 100
duration ( s) : 80 .99
input tokens: 100000
generated tokens: 200000
throughput ( req/s) : 1 .23
token throughput ( tok/s) : 2469 .32
output token throughput ( tok/s) : 2800 .00
concurrent requests: 100 .00
Token throughput ( tok/s) : 3703 .98
to First Token----------------
TTFT ( ms) : 2103 .54
TTFT ( ms) : 2216 .52
TTFT ( ms) : 3514 .77
per Output Token ( excl. 1st token) ------
TPOT ( ms) : 39 .45
TPOT ( ms) : 39 .40
TPOT ( ms) : 40 .17
Latency----------------
ITL ( ms) : 40 .56
ITL ( ms) : 38 .90
ITL ( ms) : 43 .63
==================================================
 Recommended configuration for optimizing throughput of DeepSeek-V3.2 on a single node with H200x8:
Recommended configuration for optimizing throughput of DeepSeek-V3.2 on a single node with H200x8: