Architecture
The following diagram shows the architecture of GPUStack:
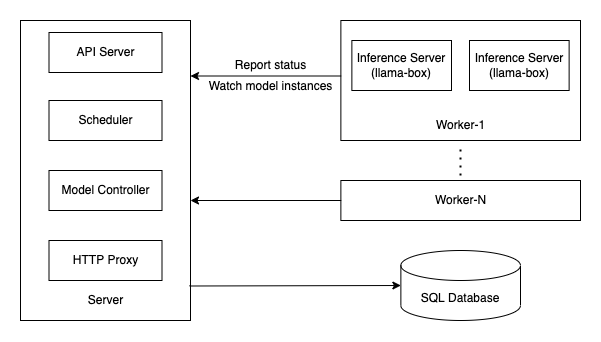
Server
The GPUStack server consists of the following components:
- API Server: Provides a RESTful interface for clients to interact with the system. It handles authentication and authorization.
- Scheduler: Responsible for assigning model instances to workers.
- Model Controller: Manages the rollout and scaling of model instances to match the desired model replicas.
- HTTP Proxy: Routes completion API requests to backend inference servers.
Worker
GPUStack workers are responsible for:
- Running inference servers for model instances assigned to the worker.
- Reporting status to the server.
SQL Database
The GPUStack server connects to a SQL database as the datastore. Currently, GPUStack uses SQLite. Stay tuned for support for external databases like PostgreSQL in upcoming releases.
Inference Server
Inference servers are the backends that performs the inference tasks. GPUStack supports llama-box and vLLM as the inference server.
RPC Server
The RPC server enables running llama-box backend on a remote host. The Inference Server communicates with one or several instances of RPC server, offloading computations to these remote hosts. This setup allows for distributed LLM inference across multiple workers, enabling the system to load larger models even when individual resources are limited.